Давно хотел процитировать замечательную статью еще 2005-го года написания: Under the Hood of J2EE Clustering. Некоторые факты, особенно касающиеся деталей работы тех или иных серверов приложений, а так же кластеризации EJB и JMS, уже порядком устарели, но общие принципы, изложенные в статье, остались неизменными.
Введение
Важно понимать, что кластер должен обеспечивать две вещи:
- Балансировку нагрузки (Load Balancing). Между вызываемым объектом и вызывающим субъектом должен находиться компонент, балансировщик нагрузки, задача которого - перераспределять запросы между разными экземплярами вызываемого объекта. Высокая доступность и высокая производительность реализуются именно данным способом.
- Преодоление отказа (Failover). Если целевой объект (т.е. тот, к которому перенаправляются вызовы) становится недоступен, то система преодоления отказов должна зафиксировать данный факт и перенаправить последующие запросы на доступные объекты. Именно данным способом реализуется отказоустойчивость.
Чтобы понять кластеризацию нужно ответить на следующие вопросы:
- какие типы объектов могут быть кластеризованы?
- где осуществляется балансировка нагрузки и преодоление отказов в моем коде?
В реальности не каждый объект может быть кластеризован и не всегда в коде осуществляется балансировка нагрузки и
преодоление отказа.
Например, рассмотрим следующий код:
public class A { ... public void business() { B instance1 = new B(); instance1.method1(); instance2.method2(); ... } } public class B { ... public void method1() { } public void method2() { } }
В данном коде вызовы методов класса B из класса A не обеспечивают ни балансировки нагрузки, ни преодоления отказа. Для обеспечения данных параметров необходим интерцептор между вызывающим и вызываемым объектами, который будет осуществлять диспетчеризацию и перенаправление запросов на различные копии объектов. Объекты классов A и B работают в одной и той же JVM и сильно связаны друг с другом. Очень сложно разместить логику диспетчеризации между ними.
Из данного примера мы видим, что кластеризации поддаются только те типы объектов, которые могут быть развернуты на распределенной системе. Балансировка нагрузки и преодоление отказов в коде реализуются только при вызове методов удаленных объектов, т.е. объектов, работающих на другой JVM.
Кластеризация на веб-уровне (фундаментальная, базовая функция J2EE-кластеризации)
Кластеризация на веб-уровне включает в себя решение следующих двух задач:
- обеспечение балансировки веб-нагрузки (Web Load Balancing);
- обеспечение гарантированного доступа к данным веб-сессии (HTTP-Session failover, репликация сессии).
Решение задачи обеспечения балансировки нагрузки раскладывается на несколько шагов:
- реализация алгоритмов балансировки нагрузки (Round-Robin, Random, Weight based...);
- проверка доступности целевых серверов;
- привязка к сессии (session stickiness) - если сессия создана на сервере 1, то все запросы в рамках данной сессии отправляются на сервер 1, пока он доступен и в состоянии их обслуживать.
Задача преодоления отказов сессии решается путем рассмотренной выше привязки к сессии (session stickness): все запросы в рамках сессии перенаправляются на тот сервер, в памяти которого хранятся данные этой сессии. Однако при недоступности данного сервера необходимо сделать так, чтобы данные сессии не пропали, а стали доступны на другом сервере, на который будут перенаправлены новые запросы в рамках данной сессии.
Чтобы реализовать такое поведение необходимо обеспечить наличие глобального идентификатора сессии, который необходим для того, что-бы не путать сессию, изначально созданную на некотором сервере с сессиями на том сервере, на который будет выполнено перенаправление запросов. Так же необходимо решить, каким образом обеспечить резервное копирование состояния сессии. Механизмы резервного копирования состояния сессии - ключевой фактор, которым отличаются разные сервера приложений. Резервное копирование сессии - процесс, требующий ресурсов процессора, сети и диска (при хранении сессий в базе данных), обеспечение данного процесса может сильно снижать производительность кластера, поэтому гаранулярность и частота копирования данных сессий являются параметрами, прямо влияющими на конкурентные преимущества того или иного сервера приложений. Например, сервер приложений JBoss в свое время передавал данные сессии по сети на все узлы кластера, а такие технологии построения веб-приложений, как JSF 1/1.2, очень способствовали применению разработчиками хранимых в сессии объектов (Session Scoped). Влияние такой взрывоопасной смеси на производительность приложений нетрудно себе представить.
Рассмотрим основные подходы к сохранению данных сессии.
- Использование СУБД через JDBC (для сериализации объектов сессии может использоваться стандартный
механизм сериализации JVM).

- Репликация в памяти (гораздо быстрее сохранения в базе данных, реализована во многих серверах приложений, таких как Tomcat, JBoss, WebLogic и WebSphere).

Данный способ приводит к отвлечению части ресурсов процессора на управление репликацией, а так же может потребовать
серьезного увеличения объема ОЗУ на хранение данных сессии, что так же влияет на работу сборщика мусора JVM.
- Подход IBM - централизованный сервер для хранения состояния. Вариация репликации в памяти, только все данные
сессии со всех серверов - участников кластера сохраняются в выделенном сервере хранения состояния.

- Подход SUN - специализированная СУБД, высокодоступная In-Memory база данных с доступом по JDBC.





Вообще производительность - это большая проблема при обеспечении восстановления данных сессии после сбоев. Поэтому обеспечить репликацию сессии в реальном времени невозможно. Очень важно выбрать правильный компромисс между доступностью данных и нагрузкой. Существует два распространенных подхода к определению времени репликации: по веб-методу - данные сессии реплицируются в конце обработки каждого запроса перед отправкой ответа клиенту, данный метод гарантирует, что данные сессии будут полностью обновлены; и по времени - задается постоянный интервал времени, по истечении которого происходит резервное копирование сессии, данный метод не дает гарантий по полному обновлению данных сессии, но увеличивает производительность, т.к. обновление происходит не после обработки каждого запроса.
На производительность так же влияет гранулярность резервного копирования. Возможны следующие варианты:
- сессия целиком;
- модифицированная сессия (вся сессия сохраняется, если ее состояние изменяется - вызываются методы session.setAttribute(), session.removeAttribute(). В приложении необходимо гарантировать, чтобы изменение данных сессии обеспечивалось только путем вызова данных методов);
- модифицированные атрибуты (сохраняются только модифицированные атрибуты сессии, что минимизирует объем данных,
требующих сохранения. Однако, чтобы работал данный метод нужно соблюдать условия: использовать для модификации сессии
только метод setAttribute() и тщательно следить за отсутствием перекрестных ссылок между атрибутами. Граф объектов для каждого атрибута сериализуется и сохраняется отдельно. Если же между двумя атрибутами есть перекрестные ссылки, то это может привести к ошибкам сериализации и десериализации, например могут быть потеряны связи между объектами. Лучше хранить как атрибут сессии только корневой объект и модифицировать только его).
Помимо перечисленных и рассмотренных подробно способов обеспечения высокой доступности данных сессии существуют и другие решения, пользующиеся той или иной популярностью:
- JRun with Jini - distributed system services, object processing, sharing and migration;
- Tangosol Coherence (сейчас - Oracle Coherence).
Реализация кластеризации JNDI
В спецификации J2EE содержится требование, согласно которому все контейнеры должны предоставлять реализацию JNDI. Основное назначение JNDI в J2EE - реализация уровня, связывающего между собой все ресурсы. Соответственно кластеризация JNDI очень важна, даже работа с EJB начинается с поиска его интерфейса в JNDI дереве. Производители серверов приложений реализуют кластеризацию JNDI по-разному в зависимости от структуры своих кластеров.
Разделяемое глобальное JNDI-дерево
Сервера приложений WebLogic и JBoss содержат глобальный распределяемый JNDI-контекст уровня кластера, который клиенты могут использовать для поиска и получения объектов. Данный контекст реплицируется на все узлы кластера с помощью IP Multicast'а, поэтому, даже если экземпляр сервера упадет, то ресурсы все равно будут доступны.

Реализуется данная структура следующим образом. На каждом узле кластера находится свое локальное хранилище JNDI. Изменения распространяются между хранилищами с помощью IP Multicast, таким образом каждый локальный сервер имен содержит копию объектов каждого другого сервера имен в своем дереве. Данная избыточная структура обеспечивает высокую доступность JNDI-дерева.
На практике данная структура может использоваться для реализации двух моментов. Во-первых, для развертывания компонентов и ресурсов, что является задачей администратора. После развертывания EJB-модуля или установки JDBC/JMS-ресурсов на одном экземпляре сервера приложений, все объекты в JNDI-дереве будут реплицированы на другие экземпляры. Во-вторых, для сохранения и извлечения разработанных программистом объектов в JNDI-дереве во время исполнения приложения с помощью специального API.
Независимые JNDI
Сервера приложений SUN JES, IBM WebSphere и некоторые другие реализуют механизм независимого JNDI-дерева для каждого экземпляра сервера приложений. Участники такого кластера не знают о наличии или отсутствии в нем других серверов. Однако, это не значит, что им не нужно JNDI-дерево уровня кластера, т.к. поскольку даже работа с EJB начинается с его поиска в JNDI-дереве, то возможности кластера нельзя использовать без кластеризации JNDI.
Независимые JNDI реализуют высокую доступность только если использующие их J2EE-приложения гомогенны. Гомогенность подразумевает, что все участники кластера имеют одни и те же настройки и на них развернуты одни и те же приложения. При соблюдении данных условий специальные инструменты администрирования, называемые агентами, помогают обеспечить высокую доступность.

И SUN JES, и IBM WebSphere имеют агентов, установленных на каждом узле кластера. При разворачивании EJB или внесении других изменений в JNDI-дерево, консоль администрирования посылает команды каждому агенту, что позволяет достигать того же эффекта, что и использование глобального JNDI-дерева.
Однако следует помнить, что независимое JNDI-дерево не поддерживает репликацию и высокую доступность объектов, которые связываются и извлекаются запущенным приложением. На это есть причина: основная роль JNDI в J2EE - обеспечивать уровень связи с администрируемыми объектами, а не являться репозиторием данных времени выполнения. Если же есть такие требования, то высокодоступный сервер LDAP или СУБД могут помочь в их реализации. И IBM, и SUN имеют собственные продукты LDAP-серверов, поддерживающие развертывание в кластерном окружении.
Централизованное JNDI
Некоторые сервера приложений используют централизованное JNDI - сервер имен распологается на одном экземпляре сервера и все участники кластера регистрируют свои EJB и другие администрируемые ресурсы на едином сервере имен.
Сервер имен самостоятельно реализует высокую доступность будучи прозрачным для клиентов. Все клиенты ищут объекты в данном сервере имен, однако такая структура усложняет установку и настройку, а так же вводит единую точку отказа, поэтому многие производители серверов приложений от нее отказываются.
Доступ к JNDI-серверу
Прежде чем начать работать с кластером, приложение-клиент должно как-то понять, как ему обращаться к нужному серверу.
Реализуется доступ путем помещения балансировщика нагрузки между клиентом и кластером JNDI, однако нужно каим-то образом приложению-клиенту указать адрес данного балансировщика. Большинство серверов приложений реализуют кластер JNDI путем указания в качестве значения параметра java.naming.provider.url списка URL'ов его участников, разделенных запятыми. Например,
java.naming.provider.url=server1:1100,server2:1100,server3:1100,server4:1100. Клиент будет пытаться получить доступ к каждому серверу в списке, перебирая их один за другим, до тех пор, пока какой-либо не ответит на его запрос. Сервер приложений JBoss так же реализует автоматическое обнаружение кластера JNDI. Если строка java.naming.provider.url пустая, то клиент будет пытаться найти JNDI-сервер, рассылая мультикаст-запросы по сети.
Реализация кластеризации EJB
Enterprise Java Beans (EJB) являются важной частью спецификации J2EE и кластеризация EJB - наиболее сложная проблема при реализации кластера J2EE.
Технология EJB вышла из области распределенных вычислений. EJB могут работать на независимых серверах, а веб-сервисы или богатые клиенты могут получить доступ к ним с других машин в сети посредством стандартного протокола RMI/IIOP. Можно вызывать методы удаленных EJB аналогично методам локальных Java-объектов. Фактически, протокол RMI/IIOP маскирует тот факт, удаленный или локальный объект вы вызываете. Это называется local/remote-прозрачностью.

Вызов EJB осуществляется через локальный объект-посредник - стаб (stub). Стабы работают на клиентской JVM и знают как получить доступ через сеть к реальным объектам посредством протокола RMI/IIOP.
Чтобы вызвать EJB в своем коде необходимо решить следующие задачи:
- запросить EJBHome-стаб из JNDI-дерева;
- запросить или создать EJB-объект посредством EJBHome-стаба. Вернется стаб EJBObject;
- осуществить вызов EJB-метода посредством стаба EJBObject.
Балансировка нагрузки и преодоление отказов реализуются на первом шаге. Во время вызовов методов EJB-стабов
(включая EJBHome и EJBObject), производители серверов приложений реализуют балансировку нагрузки и преодоление отказов тремя различными способами, рассмотренными ниже.
Умный стаб (Smart stub)
Клиент осуществляет вызов EJB посредством объекта-стаба. Данный стаб может быть извлечен из JNDI-дерева и если это реализовано, то клиент может даже скачать class-файл стаба с любого веб-сервера прозрачно. Таким образом стаб может быть сгенерирован динамически и программно во время выполнения и определение стаба (class-файл) не обязательно должно находиться в classpath клиента или быть частью клиентской библиотеки.

Сервера приложений WebLogic и JBoss реализуют кластеризацию EJB внедрением специфичного поведения в код стаба, который прозрачно работает на клиентском уровне (код клиента при этом ничего не знает о данном коде). Данная техника называется "умный стаб".
"Умный стаб" по настоящему умный, т.к. содержит список целевых экземпляров серверов, которые он может вызывать. Он может определять любые сбои на целевых экземплярах и содержит сложную логику балансировки нагрузки и преодоления отказов при диспетчеризации запросов на целевые узлы кластера. Так же стаб может обновить свой список целевых
серверов при изменении топологии кластера без внесения каких либо изменений со стороны администратора.
Данное решение обладает следующими преимуществами:
- т.к. стаб работает на клиентской стороне, то он не требует затрат ресурсов сервера на балансировку и преодоление отказов;
- балансировка нагрузки внедрена в клиентский код и зависит от жизненного цикла клиента, это устраняет единую точку
отказов в лице балансировщика - каждый клиент является своим собственным балансировщиком;
- код стаба может быть скачан динамически и может обновлять сам себя, что исключает необходимость ручного вмешательства (zero maintenance).
IIOP библиотека времени исполнения
Сервер приложений SUN JES реализует кластеризацию EJB по-другому. Логика балансировки нагрузки и преодоления отказов реализована в IIOP библиотеки времени исполнения. Например, JES содержит модифицированный класс ORBSocketFactory, который может работать в кластерном окружении (библиотека IIOP расположена на стороне клиента).
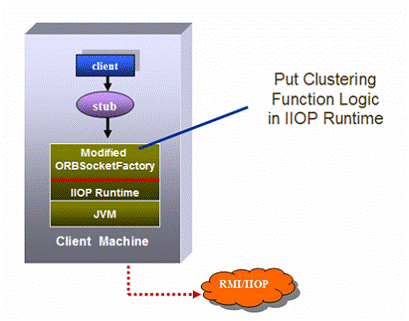
Модифицированная версия ORBSocketFactory содержит всю логику балансировки нагрузки и преодоления отказов, что позволяет самому стабу оставаться маленьким и чистым. Т.к. реализация сосредоточена в библиотеке времени выполнения, то она может использоваться из многих стабов, что экономит ресурсы. Однако данная реализация требует наличия специфичной библиотеки не клиентской стороне, что может вызвать проблемы с интероперабельностью с другими J2EE-продуктами.
Прокси-интерцептор (Interceptor Proxy)
Сервер приложений IBM WebSphere использует Location Service Daemon (LSD), который работает как прокси-интерцептор для EJB-клиентов.

При использовании данного решения клиент получает стаб с помощью JNDI. Стаб содержит информацию для маршрутизации к LSD, а не к узлу, содержащему EJB. После того, как LSD получает входящий запрос, он определяет куда его отправить на обработку, тем самым реализуя балансировку нагрузки и преодоление отказов. Данное решение требует дополнительных работ по установке и настройке.
Кластеризация Statefull Session Beans похожа на кластеризацию HTTP Session. При нормальной работе стаб EJBObject не перенаправляет запросы на другие сервера при работе с Statefull Session Beans, вместо этого он привязывается к серверу, на котором Statefull Session Bean был вызван изначально. Во время работы информация о сессии копируется и становится доступной другим участникам кластера. Если основной сервер перестает обрабатывать запросы, то их начинает обслуживать резервный сервер.
Entity beans сами по себе не содержат состояния, однако они могут обслуживать запросы от Statefull Session Beans. Все изменения данных копируются в БД с использованием встроенных механизмов Entity Beans. Таким образом для Entity Beans балансировка нагрузки и преодоление отказов может быть реализована так же как и для Stateless Session Beans. Однако, де-факто, для Entity Beans балансировка нагрузки и преодоление отказов большую часть времени не задействуются. В зависимости от используемого шаблона проектирования, Entity Beans
оборачиваются в соответствующий Session Beans-фасад, таким образом связь между SB и EB локальная по Home-интерфейсу, а значит балансировка нагрузки и преодоление отказов не задействуются.
Поддержка кластеризации JDBC и JMS ресурсов
Для данных объектов кластеризация может как поддерживаться, так и не поддерживаться.
В наше время некоторые продукты, такие как Oracle RAC, поддерживают кластеризацию, однако JDBC - это сильносвязанный протокол, который держит соединение с СУБД посредством сокетов долгое время и реализовать его кластеризацию очень тяжело. Если JDBC-соединение умирает, то все JDBC-объекты, ассоциированные с ним, так же умирают. В клиентском коде должно быть реализовано переподключение. Сервер приложений WebLogic используется мультипул JDBC для упрощения процесса переподключения.
JMS поддерживается во многих J2EE-серверах приложений, но не полностью. Балансировка нагрузки и преодоление отказов реализованы только для JMS-брокера, и только некоторые продукты реализуют функцию преодоления отказов для сообщений, находящихся в JMS Destination.
Мифы о J2EE кластеризации
- Преодоление отказов может полностью избавить от ошибок. Нет!
В принципе преодоление отказов даже не всегда нужно (пример - приложения с богатыми настолькными клиентами, способными хранить сессии у себя, в таком случае не нужно реплицировать сессию, достаточно только балансировки нагрузки). Важно понимать, что преодоление отказов работает только между вызовами методов, если ошибка возникнет во время
исполнения отдельного метода, то ее с помощью данной технологии не преодолеешь, нужны другие средства. Особенно это касается неидемпотентных методов. В серьезных приложениях очень важно сделать все методы идемпотнетными, для этого нужно использовать транзакции, проверки на существование, в случае участия нескольких систем - распределенные транзакции и т.д.
Предположим, у нас есть интернет-магазин, одновременно обслуживающий 100 пользователей. Корзины пользователей хранятся в сессии. В случае отсутствия преодоления отказов при сбое мы потеряем все 100 сессиий, а это могут быть уже заполненные корзины. Если же преодоление отказов доступа к сессии реализовано, но в момент сбоя 20% пользователей обрабатывали заказ, то да, они получат ошибку, но остальные 80 ничего не заметят. Чтобы принять решение, нужно ли реализовывать преодоление отказов, необходимо найти баланс между с одной стороны 20%, а не 100% недовольных пользователей, а с другой стороны - стоимостью реализации данной подсистемы.
- Автономные приложения могут прозрачно быть преобразованы в работающие на кластере. Нет!
Многие разработчики серверов приложений рассказывают о прозрачной кластеризации, однако в реальности необходимо подготовить приложение к работе на кластере. Нужно обеспечить: Http Session Replication (объекты в сессии должны быть сериализуемыми, при сохранении в БД нужно стремиться, чтобы объем сессии не был очень большим, а так же избегать перекресных ссылок), распределенное кэширование (чтобы изменение данных на одном узле кластера отражалось в участке кэша, хранящемся на другом узле), статические переменные (тот же синглтон, который в кластерной среде уже не будет синглтоном), доступ ко внешним ресурсам (например, распределенная файловая система) и специальным сервисам (например, к таймеру).
- Распределенные структуры (Web и EJB уровни разделены и между ними есть балансировка) более гибки чем совмещенные (collocated) (Web и EJB уровни на том же сервере, балансировка только от клиента до Web) - Скорее всего нет.
При обсуждении данного пункта интересно порассуждать о том, что если распределенные системы не быстрее и гибче совмещенных, то зачем они нужны? Соображения могут быть следующими:
- слой EJB можно использовать не только для реализации веб-приложений, но и для богатых приложений, работающих напрямую с EJB;
- EJB и Web-компоненты могут находится на разных уровнях безопасности и должны быть физически разделены. Например, между веб- и EJB-уровнем можно использовать брендмауэр;
- сильная несимметричность между веб- и EJB-уровнями. Например, есть очень сложные и требовательные к ресурсам EJB, которые могут работать только на очень мощных серверах. С другой стороны, веб-слой очень простой, чтобы на него тратить дорогие сервера. Можно купить мощные сервера для EJB-слоя и гораздо менее мощные для веб.
Выводы
Кластеризация очень сильно отличается от автономной работы. Различные производители серверов приложений используют разные подходы к ее обеспечению. Необходимо готовиться к использованию приложения на кластерном окружении с самого момента начала работы над ним. Выберите правильный продукт, подходящий под ваши требования. Так же необходимо правильно
выбрать фреймворки, подходящие для кластеризации.
Понравилось сообщение - подпишитесь на блог

Комментариев нет:
Отправить комментарий
Любой Ваш комментарий важен для меня, однако, помните, что действует предмодерация. Давайте уважать друг друга!